Have you ever recevied an email like this : “Hi this is so and so. Would you mind re-doing that analysis from two years ago by updating it for the past year?”. If you’re anything like me, this would lead to a frantic scramble in old folders to find an Excel file that you may, or more probable, may not remember exactly where the data came from. As a healthcare data analyst who performs plenty of ad-hoc analysis, this is a common experience.
Well, how to solve this issue? Enter the unsung hero : Data Management Techniques for Reproducible Research! Lost in the flashiness of statistics and machine learning algorithms, lies the most important part of any research project involving data that no one cares to talk about. The techniques needed to properly manage the data, and allow for the research to be reproducible. Since my data analyst position is not a research role, I was not familiar with this process. In this blog post, I will explain the high level techniques associated with sound data management. A process I am incorporating into my work flows, and you should too!
You can find previous assignments concerning data management techniques on my Github.
Data Management Techniques
A proper data management plan will have all the required information needed by yourself or others to locate, understand, and interpret the research in the future. While the format and content may differ, a data management plan should include all of the following :
- What data will be created?
- Who owns the data and who will have access to it?
- What formats will the data have?
- Details about the ethics committee approvals.
- Who will have access to your data and how will you protect for unnecessary access if data is sensitive/confidential in nature?
- Data organistion: File naming conventions, folder structure.
- Data storage: Where will the data be stored? Will it be backed up?
- Data sharing: Will you share your data with others? How will you do this?
A detailed checklist can be found here.
In addition to a document answering the above questions, a metadata document and thorough data dictionaries need to be included. The metadata document is a condensed version of the data management plan and can be referenced by people exploring the dataset and/or research for the first time.
Data dictionaries need to be included for any dataset used in the analysis/research. The data dictionary includes both the original and created variables. The data dictionary should include the following information about each field :
- Variable Name
- Description
- Format
- Allowable Entries
Below is a screenshot showing a simple example of a few fields :

Reproducibile Research
Creating reproducible research includes detailed documentation highlighting the data cleaning and analysis process. The method will differ between specific analysis, but the goal is always the same. In the future, anyone wishing to reproduce the research should be able to follow set steps and arrive at the same conclusion when starting with the same data. The data cleaning documentation should include :
- Data quality checks (duplicates, allowable entries, missing data, etc)
- Excluded records
- Created Variables
When possible, tables and figures should be included to illustrate the process and resulting impact on the dataset. A flowchart like below can be used :
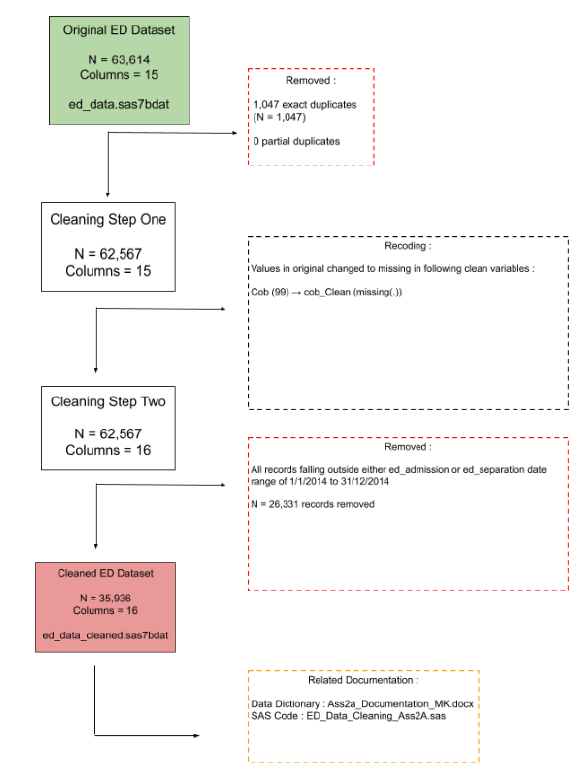
Similar to cleaning documentation, the analysis documentation should include all the steps used in the analysis to arrive at a conclusion. The logic and assumption used should always be shared, and when applicable, code should be shared to ensure consistency. Results and interpretation should also be shared to maximize the transparency of the research being conducted.
Conclusion
The process is lengthy, but the benefits outweight the initial work when conducting serious research. The consequences are lower for performing a quick ad-hoc analysis in a professional setting when compared to publishing research in a journal, but I think the techniques above should be used by analysts and researchers alike. I hope this post helped explain both the importance and some actual techniques for creating data management plans and reproducible research.